MuYi
2
性能问题的话建议自己做下profile 和监控,看下当前耗时在哪;
btw,索引建没?
您好,这个字段建索引了。现在单个语句执行耗时我这边是可以接受的,主要就是:多线程并发执行耗时比studio长
我这边的线程池连接数也够,昨天调整了graph的max_job_size,但是并没有效果,还是多线程下慢
MuYi
4
需要考虑下,cpu是不是瓶颈,内存是不是瓶颈,磁盘 io 是不是瓶颈,网络带宽是不是瓶颈
性能优化的话得看下监控,看下瓶颈在哪才好具体分析
看了服务器,磁盘、内存、cpu都没有明显异常
您说的监控是profile监控吗?
MuYi
6
能贴下单条执行和多条执行的时候的监控吗?
profile 是语句的
监控和 profile 是两个
steam
8
不一定是 nebula-dashboard,你们自建的也可以。主要看下资源消耗情况。
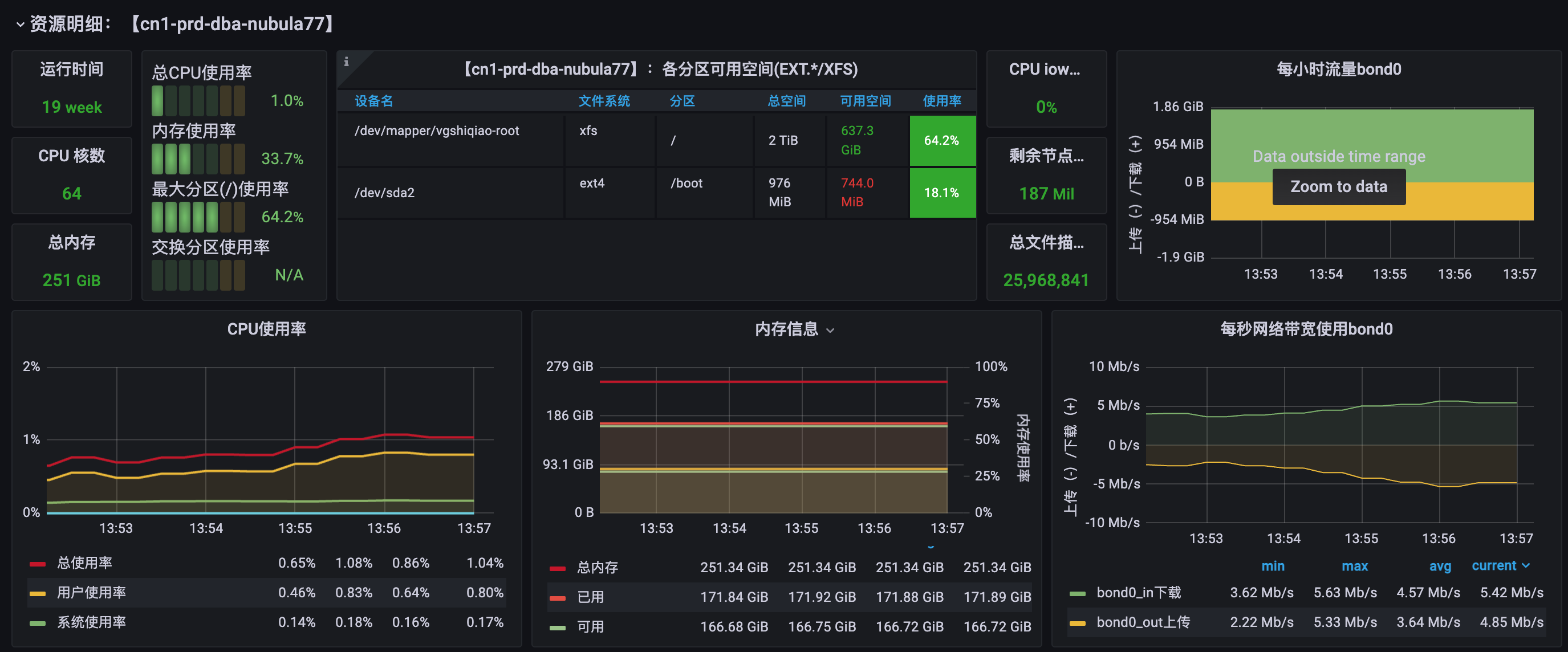
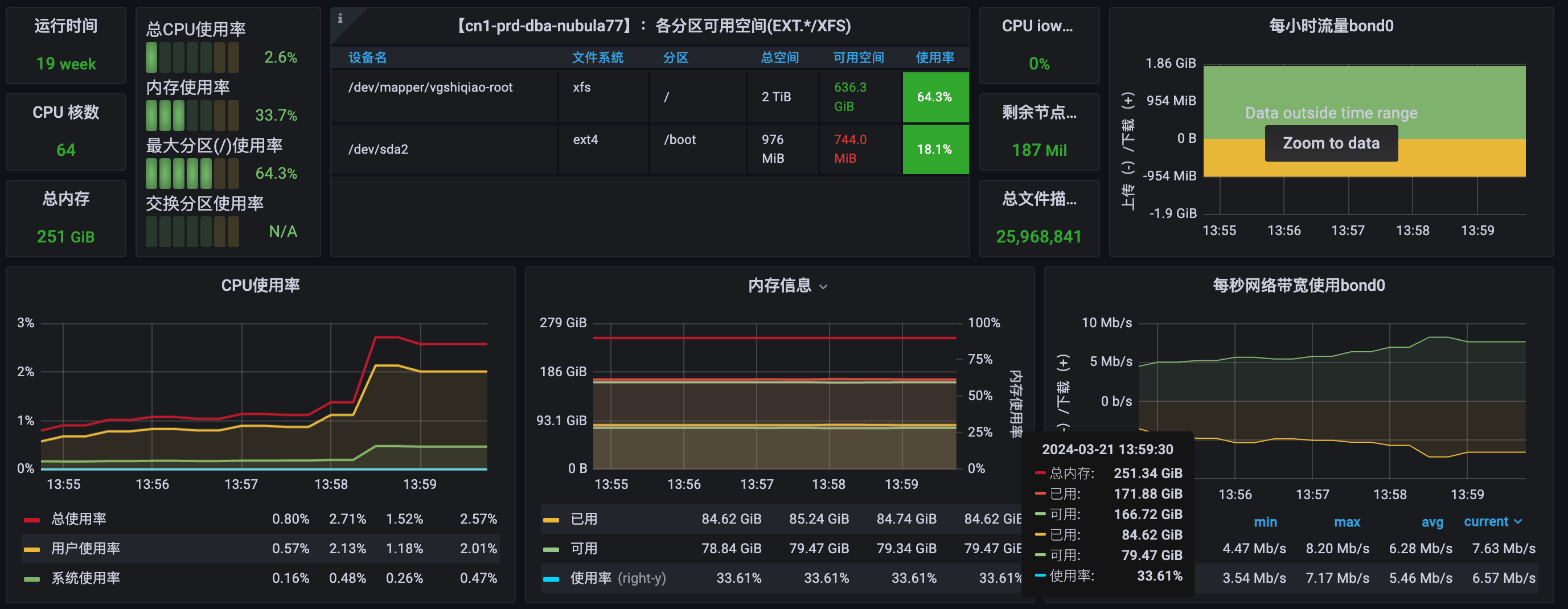
下面是我们自己监控的nebulagraph所在服务器的情况,看cpu和内存那些并没有明显的变化
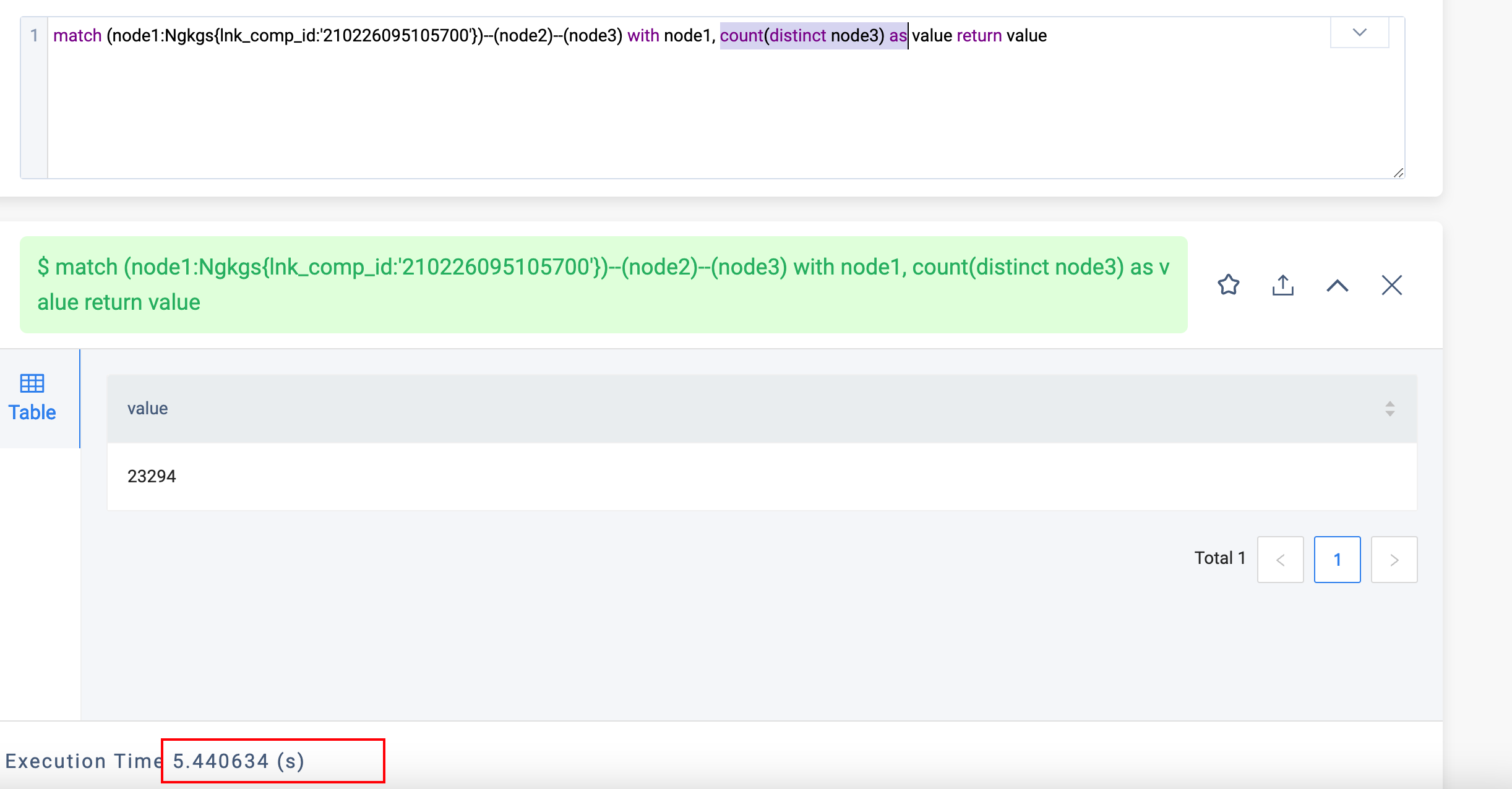
这个是单个执行的
下面这个是多条执行时的
设置graph的max_job_size会有用嘛?我们从默认值1改成8但是发现并没有效果
steam
11
你可以用 profile 加在执行语句前面,看下生成计划的耗时。可以看看执行花了多久,捞数据花了多久等等各个地方的耗时。我其实看你的问题的时候,有个疑问是,你是觉得客户端的 session pool 会增加时间开销是么?
还是说你是想优化某个执行语句本身?
我没一下子理解你的需求是啥。
steam
12
参数好像不是那么调的,正如导数据的 batch 不是越大越好一样。它应该有个最优值,而不是最大值。
我并不是想优化某个语句本身,因为我这边用的是java,我只是想不通为啥多线程执行的时候耗时会是单个执行的2-3倍
1 个赞
我这个参数是按照咱们文档上cpu核数的一半设置的
有哪些参数配置是可以提高并发的呢?比如同样的语句单独查询是5s,并发查询下也是5s左右
现在的问题就是单独查询是5s,并发查询需要10几秒
MuYi
15
我理解,有些语句如果没写好的话,会分发到所有的 storage 节点取捞数据的,这样当并发的时候,所有的节点都进行大量的操作,可能会有锁等问题。
所以如果排除了硬件问题以后,也有可能是语句或者软件实现的问题
system
关闭
16
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。